D-ESRGAN: A Dual-Encoder GAN with Residual CNN and Vision Transformer for Iris Image Super-Resolution
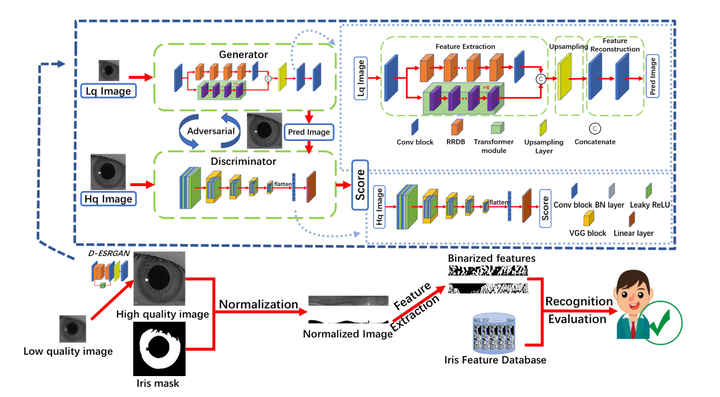 The structure diagram of D-ESRGAN
The structure diagram of D-ESRGANAbstract
Iris images captured in less-constrained environments, especially at long distances often suffer from the interference of low resolution, resulting in the loss of much valid iris texture information for iris recognition. In this paper, we propose a dual-encoder super-resolution generative adversarial network (D-ESRGAN) for compensating texture lost of the raw image meanwhile maintaining the newly generated textures more natural. Specifically, the proposed D-ESRGAN not only integrates the residual CNN encoder to extract local features, but also employs an emerging vision transformer encoder to capture global associative information. The local and global features from two encoders are further fused for the subsequent reconstruction of high-resolution features. During the training, we develop a three-stage strategy to alleviate the problem that generative adversarial networks are prone to collapse. Moreover, to boost the iris recognition performance, we introduce a triplet loss to push away the distance of super-resolved iris images with different IDs, and pull the distance of super-resolved iris images with the same ID much closer. Experimental results on the public CASIA-Iris-distance and CASIA-Iris-M1 datasets show that D-ESRGAN archives better performance than state-of-the-art baselines in terms of both super-resolution image quality metrics and iris recognition metric.